2 Computational Thinking
2.1 Why computational thinking
If social scientists want to learn how to work smart—not just hard—they need to take full advantage of the power of modern programming languages. That power is automation.
Let’s consider the following two cases (adapted from a column I contributed to the UC Berkeley D-Lab website):
- Case 1: Suppose a social scientist needs to collect data on civic organizations in the United States from websites, IRS reports, and social media posts. Because the number of these organizations is large, the researcher cannot gather significant data from multiple sources alone. So, they hire undergraduates and assign tasks. This is a typical, labor-intensive plan in social science. Automation is not part of the game plan—even though it should be. The high cost means others are unlikely to replicate or update the effort.
Case 1 shows that it is difficult to ensure reproducibility and scalability without efficient data analytics pipelines.
- Case 2: An alternative approach is to write code that automatically collects, parses, and stores the data in a structured database. A researcher might also maintain and validate the data infrastructure. This lowers costs, boosts reproducibility, and increases scalability. Code can be documented, uploaded to GitHub, or turned into open-source libraries.
Case 2 demonstrates the advantages of automation and its usefulness to both the academic community and the broader public. I used this approach in my paper co‑authored with Hahrie Han and Milan de Vries, published in Nature Human Behaviour (2023).
To realize these benefits, one must learn to program. In the age of data science, programming is as valuable to social science as writing. A research process’s efficiency, reproducibility, and scalability often depend on how much of it can be automated.
Here’s an insightful quote from Hadley Wickham, who received the 2019 COPSS Presidents’ Award for his contributions to statistics through the tidyverse:
Every modern statistical and data analysis problem needs code to solve it. You shouldn’t learn just the basics of programming—spend some time gaining mastery. Improving your programming skills pays off because code is a force multiplier: once you’ve solved a problem once, code allows you to solve it much faster in the future. As your programming skill increases, the generality of your solutions improves: you solve not just the precise problem you encountered, but a wider class of related problems (in this way programming skill is very much like mathematical skill). Finally, sharing your code with others allows them to benefit from your experience.
— Hadley Wickham
That said, social scientists do not need to become software engineers. Programming is a means, not an end. Readers should ask: which parts of the research process can be automated? Programming is just a way to teach a machine to perform those tasks.
Teaching a computer to perform a task requires computational thinking, which Jeannette Wing defines as:
“Formulating a problem and expressing its solution in a way that a computer—human or machine—can effectively carry out.”
(Jeannette M. Wing, 2006)
This means understanding how computers think about and process data.
2.2 Computational thinking in the age of generative AI
Large language models such as ChatGPT are powerful, but they do not remove the need for computational thinking. On the contrary, they make it more important:
LLMs can make things up.
They sometimes give answers that sound right but are wrong. A quick script that checks the answer against a small, trusted dataset will catch these slips.-
Good prompts need structure.
Think of a prompt as a little recipe:- get the data,
- give a short summary,
- save the result.
Writing that tiny recipe is exactly the “break‑it‑into‑steps” habit that computational thinking builds.
- get the data,
Clean data in → clean answer out.
If we feed the AI messy text or numbers, we get messy results back. A simple “read → tidy → save” pipeline keeps things neat and repeatable.Many AI calls cost time and money.
Saving (caching) answers you already have and running repeated jobs side‑by‑side (parallel) makes the process faster and cheaper—no fancy code required.Tools change fast.
Today it’s ChatGPT; tomorrow it’s something new. When you know how to frame any task as “input → steps → output,” swapping in a new tool is easy.
In short, generative AI is a tool, not a replacement for the disciplined way of breaking problems into parts so that both humans and machines can solve them reliably.
2.3 How to teach and learn computational thinking
This book teaches computational thinking through incremental steps:
- From graphical user interfaces to command-line tools (Chapter 3)
- From short programs to longer, structured programs (Chapters 4–5)
- Toward solving large, complex problems using computational methods (Chapters 6–7)
The focus is on practical programming concepts. As John Chambers (creator of S, the predecessor of R) explained:
“[W]e wanted users to be able to begin in an interactive environment, where they did not consciously think of themselves as programming. Then as their needs became clearer and their sophistication increased, they should be able to slide gradually into programming, when the language and system aspects would become more important.”
— Stages in the Evolution of S
A few important reminders for learners:
Beginners! Learning programming is a long game. Consistency matters. Keep writing code, even if it’s imperfect.

Intermediate programmers! Empower, don’t intimidate. The most important rule in computational social science is to be kind. See David Robinson’s “A Million Lines of Bad Code” for more perspective.

Finally, have fun. I’ve described why programming matters—but I know that’s not enough to motivate everyone, especially those who’ve had difficult experiences with STEM. So I try to keep materials as accessible as possible by emphasizing two principles: the BIG PICTURE and the WORKFLOW.
Together with Margaret Ng, I wrote about these teaching principles in an article published in PS: Political Science and Politics (APSA’s journal on professional development).
Here’s a short summary of why inclusive programming instruction matters:
Showing the big picture: Always remind students of the types of input and output data involved. Students with Excel, SPSS, or Stata backgrounds may not be used to thinking about data structure. They need guideposts to avoid common mistakes (e.g., passing a character vector when a numeric one is needed) and to see how different tools (e.g., APIs and web scraping) connect.
Walking through the workflow: Break down the steps needed to go from raw input to clean output. This helps students feel less overwhelmed and more capable of applying the same logic to new problems. Teaching workflows—especially by composing reusable functions—is key to helping students grow from beginners into intermediate programmers who write clear, reproducible code.
2.4 Computational thinking and a career in computational social science
If you are considering a career in computational social science (CSS), take a look at the guide I co‑authored with Aniket Kesari (Fordham Law), Sono Shah (Pew Research Center), Taylor Brown (Meta), Tiago Ventura (Georgetown), and Tina Law (UC Davis).
Our article in PS: Political Science & Politics (2024) recommends that PhD students augment traditional social‑science training with three CSS pillars:
-
Build data‑science skills — automate data collection, cleaning, modelling, and visualization.
-
Create a public portfolio — showcase projects that use code to answer substantive social‑science questions.
- Join CSS networks — connect with computational social scientists across academia, industry, and the public sector.
We close with practical suggestions for departments and professional associations to help students follow this path.
A tutorial based on the paper was presented at IC2S2 2024.
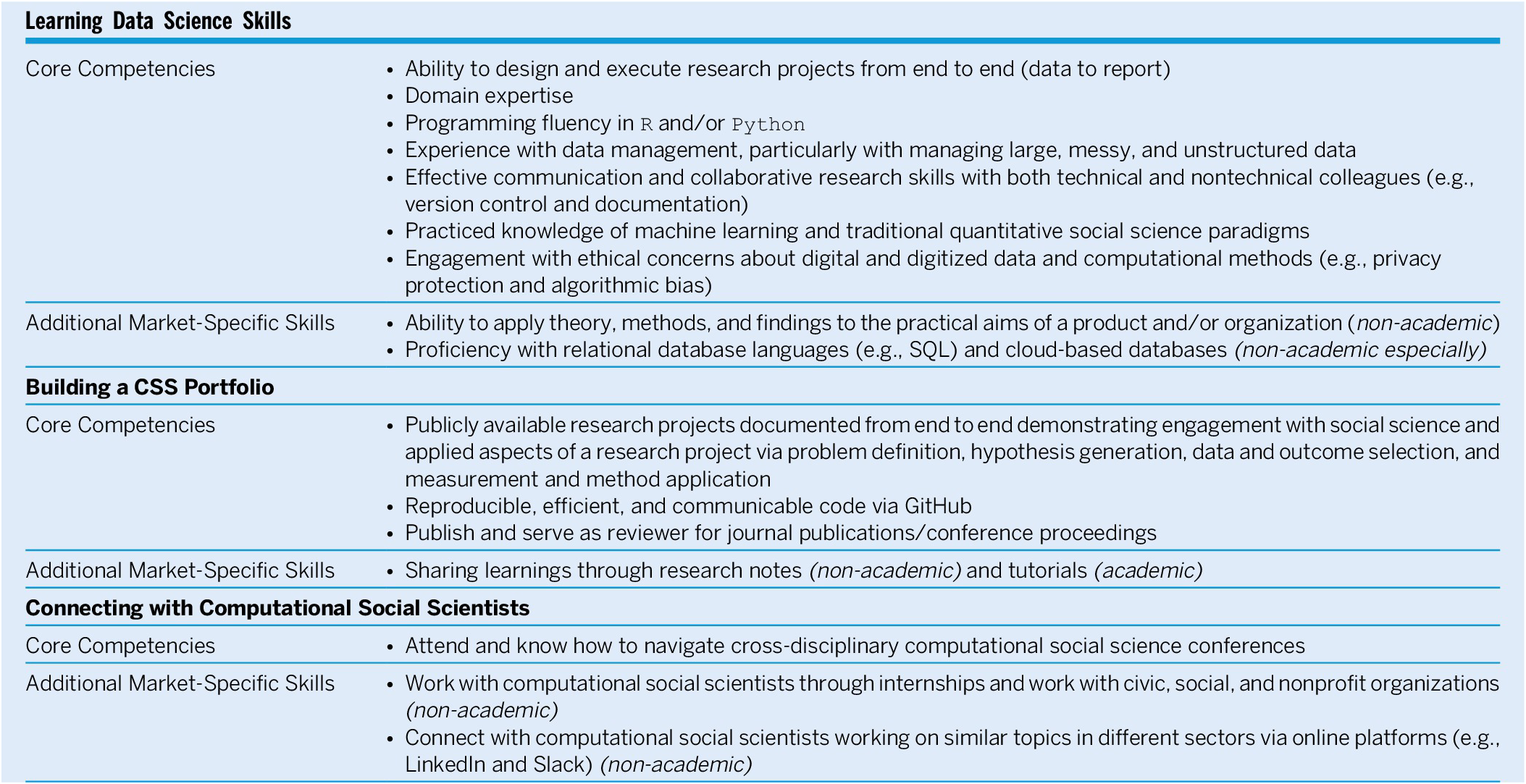
Computational Social Science Professionalization Process (Kesari, Kim, Shah, Brown, Ventura, and Law 2024: 102).